Журнал «Компьютерра» №37 - Страница 14
При неправильном предсказании конвейер обычно приходится «сбрасывать», каким-то образом восстанавливая состояние процессора, предшествующее моменту неправильного перехода. А ведь пока исполнялась неправильная ветка, там ого-го сколько всего могло случиться! Неправильный опкод (нераспознаваемая машинная инструкция), обращение к виртуальной памяти (провоцирующее исключение в процессоре), некстати распознанное деление на ноль (тоже ошибка). Все это приходится тщательно отслеживать и проверять, причем это не шутки: одно время из-за ошибки в реализации конвейера процессора AMD K5, программист, написавший конструкцию если x A 0, то y = 1/x, иначе y = 0, запросто мог получить при x @ 0 на, казалось бы, ровном месте ошибку «деление на ноль», вызванную неправильным предсказанием перехода. А в OoO-процессорах ситуация еще сложнее - пока «тормозит» не вовремя отправившаяся за операндами в оперативную память инструкция, процессор успевает пропустить вперед, выполнить и едва ли не сохранить результат вычисления десятков инструкций неправильной ветки: попробуй за всем этим уследить!
Но бороться здесь есть за что: для современных процессоров каждая ошибка предсказания - это десятки вхолостую израсходованных тактов. Сущая катастрофа, если учитывать, что за каждый такт можно было бы исполнить до трех x86-инструкций и совершить кучу вычислений. Если бы блока предсказания не было, то так «тормозил» бы каждый условный переход.
Точность предсказания современных блоков составляет на тестах SPEC порядка 98-99%. Может показаться, что совершенствовать блок не имеет смысла, но это не совсем так. Дело в том, что на производительности гораздо больше сказывается процент ошибок, а не верных предсказаний. А переход от 98-процентной точности к 99-процентной означает двукратное снижение ошибок - с 2% до 1%! Поэтому если вы внимательно почитаете пресс-релизы о новых CPU, то заметите, что «усовершенствованный блок предсказания переходов» упоминается в них почти всегда.
В архитектуре IA-64 техника предсказания переходов сделала значительный шаг вперед - эти процессоры умеют одновременно вычислять несколько веток программного кода. То есть, встретив инструкцию условного перехода, процессор начинает «охотиться за двумя зайцами» - просчитывать оба варианта развития событий вплоть до того момента, пока не станет ясно, какой из них правильный. Поскольку инструкции «разных вариантов» практически не зависят друг от друга, а исполнительные устройства Itanium обычно загружены далеко не полностью, то исполнять побочную ветку нередко удается практически с той же скоростью, что и основную, так что даже при неправильном предсказании условного перехода происходит не остановка процессора на пару десятков тактов, а всего лишь снижение производительности на небольшом участке кода.
Архитектура PowerPC
Последняя из ныне здравствующих процессорных RISC-архитектур - это, конечно же, знаменитая PowerPC, детище альянса Apple, IBM и Motorola (AIM). Сегодня на PowerPC есть четкие спецификации, следуя которым любой желающий может разработать совместимый с ним процессор. Ничего особо интересного в нем нет - это самый что ни на есть классический RISC-процессор без специальных «примочек». Существуют 32- и 64-разрядные версии PowerPC (причем 64-разрядные совместимы с 32-разрядным кодом), а равно и ряд стандартизованных расширений (типа эппловского набора инструкций AltiVec). В то время как MIPS и ARM «специализировались» на тех или иных применениях, PowerPC, подобно x86, позиционировалась в основном для обычных персоналок и серверов. Вплоть до 2001 года x86 и PowerPC развивались более или менее синхронно, однако из-за технологических проблем и неспособности угнаться за процессорами AMD и Intel в «гонке мегагерц» PPC шаг за шагом сдавала позиции. А исчерпав «запас прочности» и застряв на частотах 1,0-1,4 ГГц, она стала стремительно проигрывать архитектуре x86, по-прежнему сохранявшей высокие темпы развития из-за ожесточенной схватки Intel и AMD. Поскольку «отступать» PowerPC было в общем-то некуда (нишу интегрированных процессоров оккупировали ARM и MIPS), то многие посчитали ее верным кандидатом на вымирание. Даже Apple недавно «отреклась» от своей архитектуры, переметнувшись в стан приверженцев x86. Только крайне дорогие серверные процессоры POWER, выпускавшиеся на пределе технологических возможностей Голубого гиганта (Power4, в частности, стали первыми в мире двухъядерниками), еще довольно уверенно чувствуют себя в линейке продуктов IBM.
Однако ситуация, похоже, начала меняться: именно архитектура PowerPC положена в основу будущих многоядерных процессоров всех игровых приставок шестого поколения (от Sony, Microsoft и Nintendo), поскольку ни MIPS, ни тем более ARM на эту роль не годятся; процессоры Intel в их текущем варианте плохо подходят для создания игровых приставок нового поколения; о процессорах AMD и говорить не приходится - компания просто не в состоянии обеспечить достаточный объем их производства. Вот и остается единственным кандидатом на роль нового «суперпроцессора» только всем доступная, технологически более простая, нежели x86, и достаточно производительная архитектура PowerPC. Что еще важнее для PPC, именно она положена в качестве аппаратной основы концепции Cell, которая, возможно, станет следующим шагом в развитии компьютинга. Так что пожелаем РРС удачи - от наличия на рынке множества альтернатив пользователи только выигрывают, и видеть в обозримом будущем абсолютную монополию x86, даже в варианте AMD64, лично мне не хотелось бы.
Устройство процессоров AMD архитектуры K8
Архитектура K8 используется во всех современных серверных, десктопных и мобильных процессорах AMD (Opteron, Sempron, Athlon 64 и Athlon 64 X2). Эффективная длина конвейера[Время в тактах от начала исполнения инструкции до момента, когда результаты выполнения будут записаны в оперативную память] варьируется от 10-12 стадий (для целочисленных, логических вычислений и обращений к оперативной памяти) до 17 стадий (вычисления с плавающей точкой). Количество одновременно исполняемых инструкций за такт в устоявшемся режиме - до трех; тактовые частоты серийно выпускаемых процессоров - от 1,6 до 2,8 ГГц.
Об особенностях организации архитектуры K8, связанных с интегрированным контроллером памяти, линками HyperTransport и неоднородной моделью памяти SUMa мы подробно писали в статье про двухъядерные процессоры; в остальном же - перед нами вполне классический процессор Гарвардской архитектуры. Объем кэшей L1 D-cache (для данных) и L1 I-cache (для кода) - фиксирован и составляет по 64 Кбайт; имеется общий эксклюзивный[Эксклюзивным называется кэш, в котором данные, хранящиеся в кэш-памяти первого уровня, не обязательно должны быть продублированы в кэшах нижележащих уровней. Инклюзивный кэш - когда любая информация, хранящаяся в кэшах высших уровней, дублируется в кэш-памяти нижележащих] кэш второго уровня объемом от 128 до 1024 Кбайт; кэш третьего и более низких уровней не предусмотрен, но в рамках протокола MOESI процессоры в многопроцессорных системах могут обращаться к кэш-памяти других процессоров.
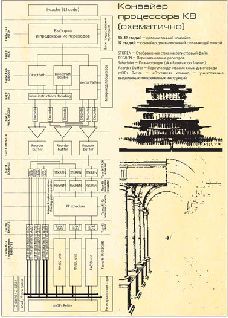
Исполнение инструкций на конвейере K8, как и положено, начинается с блока выборки инструкций. За один такт блок выбирает из кэша 16 байт данных и выделяет из них от одной до трех инструкций x86 - сколько в выбранных данных поместилось[Поскольку средняя длина инструкции x86 составляет 5-6 байт, то, как правило, блоку удается выбрать три инструкции за такт]. Чтобы облегчить процесс декодирования, инструкции, хранящиеся в кэшах L1, тегированы - в линейках кэша сохраняется информация о том, как внутри этой линейки распределены инструкции x86. Попутно с помощью блока предсказания переходов в этом же такте определяется адрес блока, с которого начнется выборка в следующем такте. Тегирование производится при выборке данных из кэша L2 в кэш L1 I-cache; при вытеснении данных из L1 в L2 теги сохраняются.