Рассказы о математике с примерами на языках Python и C - Страница 15
Математически, оба напряжения связаны простой формулой:
Действительно, 220 * √3 = 380.
Кстати, обрыв нулевого провода в доме — серьезная неисправность, из-за чего в квартиры может быть подано линейное напряжение, составляющее те самые 380 В. Такой случай произошел лично с автором, впрочем ущерб оказался невелик, перегорели лишь настенные электронные часы и несколько блоков питания. Но при отсутствии в доме людей это может привести и к пожару, такие случаи не редкость. Так что тем, у кого в квартире старая проводка, рекомендуется установить в электрощиток устройство защиты от перенапряжения, его цена невелика, и явно дешевле ремонта в квартире.
19. Приложение 1 - Вычисления с помощью видеокарты
Еще 20 лет назад, во времена процессоров 80386, пользователям приходилось покупать математический сопроцессор, позволяющий быстрее выполнять вычисления с плавающей точкой. Сейчас такой сопроцессор покупать уже не надо — благодаря прогрессу в игровой индустрии, даже встроенная видеокарта компьютера имеет весьма неплохую вычислительную мощность. Например, даже бюджетный видеочип Intel Graphics 4600 имеет 20 вычислительных блоков, что превышает количество ядер «основного» процессора. Разумеется, каждое ядро GPU по отдельности слабее CPU, но здесь как раз тот случай, когда количество дает преимущество над качеством. Вычисления с помощью GPU сейчас очень популярны — от майнинга биткоинов до научных расчетов, диапазон ценовых решений также различен, от «бесплатной» встроенной видеокарты до NVIDIA Tesla ценой более 100 тыс. рублей. Поэтому интересно посмотреть, как же это работает.
Есть две основные библиотеки для GPU-расчетов — NVidia CUDA и OpenCL. Первая обладает большими возможностями, однако работает только с картами NVIDIA. Библиотека OpenCL работает с гораздо большим числом графических карт, поэтому мы рассмотрим именно ее.
Основной принцип GPU-расчетов — параллельность вычислений. Данные, хранящиеся в «глобальной памяти» (global & constant memory) устройства, обрабатываются модулями (каждый модуль называется «ядром»), каждый из которых работает параллельно с другими. Модуль имеет и свою собственную память для промежуточных данных (private memory). Так это выглядит в виде блок-схемы:
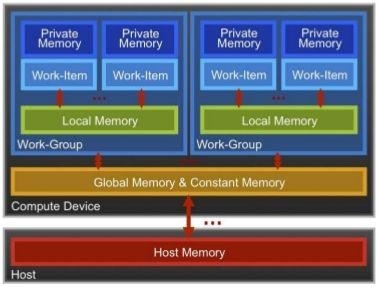
Таким образом, если задача может быть разбита на небольшие блоки, параллельно обрабатывающие небольшой фрагмент блока данных, такая задача может эффективно быть решена на GPU.
Рассмотрим пример: необходимо проверить, какие числа в массиве являются простыми. Массив может быть большим, например миллион элементов. Такая задача идеальна для распараллеливания: каждое число может быть проверено независимо от предыдущего.
Для решения такой задачи с помощью OpenCL необходимо выполнить ряд шагов.
1. Написать код микроядра (kernel):
Этот код будет запускаться непосредственно на графических процессорах видеокарты. Код пишется на языке C. В данном примере мы для упрощения храним код прямо в виде строки в программе.
const char *KernelSource = "n"
"__kernel void primes( n"
" __global unsigned int* input, n"
" __global unsigned int* output) n"
"{ n"
" unsigned int i = get_global_id(0); n"
" //printf("Task-%d\n", i); n"
" output[i] = 0; n"
" unsigned int val = input[i]; n"
" for(unsigned int p=2; p<=val/2; p++) { n"
" if (val % p == 0) n"
" return; n"
" } n"
" output[i] = 1; n"
"} n"
"n";Суть кода проста. Массив input хранит числа, которые нужно проверить, функция
get_global_id01output2. Инициализировать подготовку вычислений:
int gpu = 1;
clGetDeviceIDs(NULL, gpu ? CL_DEVICE_TYPE_GPU : CL_DEVICE_TYPE_CPU, 1, &device_id, NULL);
cl_context context = clCreateContext(0, 1, &device_id, NULL, NULL, &err); cl_command_queue commands = clCreateCommandQueue(context, device_id, 0, &err);На этом этапе можно выбрать где будут производиться вычисления, на основном процессоре или на GPU. Для отладки удобнее основной процессор, окончательные расчеты быстрее на GPU.
3. Подготовить данные:
#define DATA_SIZE 1024
cl_uint *data = (cl_uint*)malloc(sizeof(cl_uint) * DATA_SIZE);
cl_uint *results = (cl_uint*)malloc(sizeof(cl_uint) * DATA_SIZE);4. Загрузить данные и программу из основной памяти в GPU:
cl_program program = clCreateProgramWithSource(context, 1, (const char **) & KernelSource, NULL, &err);
clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
cl_kernel kernel = clCreateKernel(program, "primes", &err);
cl_mem output = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(cl_uint) * count, NULL, NULL);
clEnqueueWriteBuffer(commands, input, CL_TRUE, 0, sizeof(cl_uint) * count, data, 0, NULL, NULL);
clSetKernelArg(kernel, 0, sizeof(cl_mem), &output);
clGetKernelWorkGroupInfo(kernel, device_id, CL_KERNEL_WORK_GROUP_SIZE, sizeof(local), &local, NULL);5. Запустить вычисления на GPU и дождаться их завершения:
global = DATA_SIZE;
clEnqueueNDRangeKernel(commands, kernel, 1, NULL, &global, &local, 0, NULL, NULL);