Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews - Страница 7
В столбце F дается фактический F-критерий Фишера, который находится путем сопоставления факторной и остаточной дисперсии на одну степень свободы. При этом F-критерий Фишера рассчитывается по формуле (2.15):
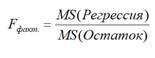
Если нулевая гипотеза (об отсутствии связи между переменными, включенными в уравнение регрессии) справедлива, то факторная и остаточная дисперсия не отличаются друг от друга. Поэтому для того чтобы уравнение регрессии было признано значимым, для нулевой гипотезы требуется опровержение, а для этого необходимо, чтобы факторная дисперсия превышала остаточную дисперсию в несколько раз. Статистиками разработаны соответствующие таблицы критических значений F-критерия при разных уровнях значимости нулевой гипотезы и различном числе степеней свободы. При этом следует иметь в виду, что табличное значение F-критерия – это максимальная величина отношения факторной дисперсии к остаточной дисперсии, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы. Если фактический (то есть рассчитанный для этого уравнения регрессии) F-критерий больше его табличного значения, то нулевая гипотеза об отсутствии связи между результативном признаком и факторами отклоняется. И в этом случае делается вывод о существенности этой связи.
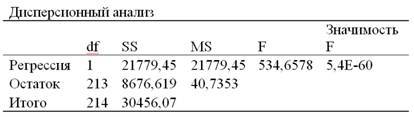
5.В столбце значимость F показывается уровень значимости, который соответствует величине фактического F-критерия Фишера, вычисленного для данного уравнения регрессии. В нашем случае значимость F факт. практически равна нулю, то есть F факт. больше F табл. (значения F-критерия Фишера при уровне значимости 0,05 или 5% можно найти в любом учебнике по статистике) при 1% и 5 % уровне значимости. Отсюда можно сделать вывод, о статистической значимости уравнения регрессии, поскольку связь между включенными в него факторами в данном случае доказана.
В тех случаях, когда значимость F бывает больше, например, 0,01, но меньше 0,05, то тогда делается вывод, что F факт. меньше F табл. при 1% уровне значимости, но больше F табл при 5 % уровне значимости. Следовательно, в этой ситуации нулевая гипотеза об отсутствии связи между результативным признаком и факторами, включенными в уравнение регрессии, на 1% уровне значимости не отклоняется, но отклоняется на 5 % уровне значимости. Таким образом, в этом случае каждый исследователь должен сам решить, считать ли 5% уровень значимости F-критерия достаточным для того чтобы сделать вывод о статистической значимости данного уравнения регрессии. При этом следует иметь в виду, что если значимость F-критерия выше 0,05, то есть F факт. меньше F табл. при 5% уровне значимости, то в этой ситуации уравнение регрессии, как правило, считается статистически незначимым.
Таблица 2.3 «Дисперсионный анализ»
В таблице 2. 4 сгенерированы коэффициенты уравнения регрессии и оценки их статистической значимости.
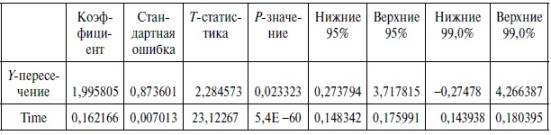
1. При этом в столбце Коэффициенты представлены коэффициенты уравнения регрессии. На пересечении этого столбца со строкой Y-пересечение дан свободный член, который в формуле линейного уравнения регрессии (6) обозначен символом а =1,995805.
Во второй строке данного столбца, обозначенной как Time (независимая переменная – порядковый номер месяца), сгенерирован коэффициент уравнения регрессии, который в формуле (6) представлен символом b =0,162166.
Таким образом, данные, представленные в столбце Коэффициенты, дают нам возможность составить – путем подстановки соответствующих цифр в формулу (2.2) – следующее уравнение линейной парной регрессии:
y = 0,1622x + 1,9958;
где независимая переменная x означает порядковый номер месяца (июнь 1992 г. =1, а апрель 2010 г. = 215), а зависимая переменная y – ежемесячное значение курса доллара.
При этом экономическая интерпретация данного линейного уравнения следующая: в период с июня 1992 по апрель 2010 г. курс доллара к рублю ежемесячно рос со средней скоростью 16,22 коп. при исходном уровне временного ряда в размере одного рубля и 99,58 коп. В свою очередь, геометрическая интерпретация данного линейного уравнения следующая: свободный член уравнения =1,9958 показывает точку пересечения линии тренда с осью Y, а коэффициент уравнения 0,1622x равен углу наклона линии тренда к оси X.
Таблица 2.4. Коэффициенты уравнения регрессии и их статистическая значимость
2. В столбце СТАНДАРТНАЯ ОШИБКА сгенерированы стандартные ошибки свободного члена и коэффициента регрессии, значения которых даны в предыдущем столбце табл. 4. При этом стандартная ошибка свободного члена уравнения регрессии находится по формуле (2.16):
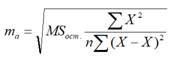
где MS ост.= D ост. – остаточная дисперсия на одну степень свободы. Для нашего случая стандартная ошибка свободного члена уравнения регрессии вычисляется следующим образом:

В свою очередь, стандартная ошибка коэффициента регрессии оценивается по формуле (2.17):
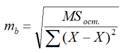
Для нашего случая стандартная ошибка коэффициента регрессии рассчитывается таким образом:
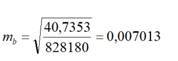
3. В столбце t-СТАТИСТИКА даны расчетные значения t-критерия. При этом для свободного члена t-статистика вычисляется по формуле (2.18):
где a – коэффициент свободного члена уравнения.
В нашем случае t-статистика находится следующим образом:
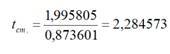
Для коэффициента регрессии t-статистика рассчитывается по формуле (2.19):
где b – коэффициент регрессии
В нашем случае t-статистика находится следующим образом:
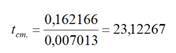
4. В столбце Р-ЗНАЧЕНИЕ сгенерированы уровни значимости, соответствующие вычисленным в предыдущем столбце значениям t-статистики.
В Excel Р-значение находится с помощью следующей функции:
СТЬЮДРАСП (Х=tст.;df=n-k-1;хвосты=2);
где в опции Х дается t-статистика, для которой нужно вычислить двустороннее распределение; в опции df – число степеней свободы; в опции хвосты – цифра 2 для двустороннего распределения.